Don Ross
2.5. Các khái niệm giải pháp và những cân bằng
Trong nan đề người tù, các kết quả mà chúng ta thể hiện là (2,2) bằng cách chỉ ra sự đào ngũ chung thì được coi là giải pháp của trò chơi. Đi theo các thực tiễn chung trong kinh tế học, các lý thuyết gia trò chơi đã coi các giải pháp trò chơi là những cân bằng. Những người đọc có tư duy triết học sẽ muốn đưa ra một vấn đề khái niệm ngay trong trường hợp này: cái gì “được cân bằng” đối với một số kết quả trò chơi như cái mà chúng ta đang có động cơ để gọi chúng là “các giải pháp”?
Khi chúng ta nói rằng một hệ thống vật chất nằm trong sự cân bằng thì có nghĩa là chúng ta muốn nói rằng nó đang ở trong trạng thái bền vững, đó là một trạng thái mà toàn bộ các lực nhân quả bên trong hệ thống cân bằng với bên ngoài và vì vậy mà để nó ở trạng thái “nghỉ” cho đến khi và trừ khi nó bị xáo trộn bởi sự can thiệp của một lực lượng ngoại sinh nào đó. Đó chính là cái mà các nhà kinh tế quan niệm một cách truyền thống là “cân bằng”; họ đọc các hệ thống kinh tế như là các mạng lưới của những mối quan hệ nhân quả, giống hệt như các hệ thống vật chất và các cân bằng của những hệ thống như vậy chính là những trạng thái bền vững nội sinh. Như chúng ta sẽ thấy sau khi thảo luận về lý thuyết trò chơi tiến hóa trong phần sau thì chúng ta có thể bảo lưu một cách hiểu như vậy về sự cân bằng trong trường hợp lý thuyết trò chơi. Tuy nhiên như chúng ta đã lưu ý ở phần 2.1, một số người đã giải thích lý thuyết trò chơi là một lý thuyết diễn giải về sự suy lý chiến lược. Đối với họ, một giải pháp cho một trò chơi phải là một kết quả mà một tác nhân duy lý phải tiên đoán được bằng cách sử dụng duy nhất các cơ chế tính toán duy lý. Các lý thuyết gia như vậy phải đối mặt với một số mắc míu về những khái niệm giải pháp không phải là quá quan trọng đối với những người hành vi luận. Chúng ta sẽ xem xét những mắc míu như vậy và những giải pháp khả thể trong suốt cả phần còn lại của bài viết này.
Sẽ là hữu dụng để bắt đầu cuộc thảo luận từ trường hợp PD [Nan đề người tù], vì nó đơn giản đến mức bất ngờ nếu xem xét từ quan điểm của những rắc rối này. Cái mà chúng ta coi như là giải pháp của nó chính là cân bằng Nash của trò chơi. (Từ Nash ở đây chính là John Nash, nhà toán học được giải Nobel trong Nash 1950 đã mở rộng nhất và khái quát hóa công trình tiên phong của von Newmann và Morgenstern). Cân bằng Nash từ đây gọi là NE được áp dụng (hoặc thất bại trong khi áp dụng vào toàn bộ các tập chiến lược, mỗi tập cho một người chơi trong một trò chơi. Một tập chiến lược là một cân bằng Nash chỉ trong trường hợp không người chơi nào có thể cải thiện được khoản phải trả của họ, những chiến lược nhất định của tất cả những người chơi khác trong trò chơi bằng cách thay đổi chiến lược của người chơi. Hãy lưu ý xem tư trưởng này gắn liền với tư tưởng về sự thống trị nghiêm nhặt đến mức nào: không chiến lược nào có thể là chiến lược cân bằng Nash nếu nó bị thống trị một cách nghiêm nhặt. Vì vậy nếu việc loại bỏ lặp lại những những chiến lược thống trị nghiêm nhặt đưa chúng ta đến với một kết quả duy nhất thì chúng ta biết rằng chúng ta đã phát hiện ra cái cân bằng Nash duy nhất của trò chơi đó. Giờ đây hầu hết các lý thuyết gia đều đồng ý rằng việc tránh những chiến lược thống trị nghiêm nhặt là một yêu cầu tối thiểu của tính duy lý. Điều này ám chỉ rằng nếu một trò chơi có một kết quả là một cân bằng Nash duy nhất như trong trường hợp cùng nhận tội trong trò chơi PD, thì nó phải là một giải pháp duy nhất của nó. Đây là một trong những khía cạnh quan trọng nhất trong đó trò chơi PD là một trò chơi “dễ” (và phi điển hình).
Chúng ta có thể xác định một lớp các trò chơi trong đó cân bằng Nash luôn luôn không chỉ cần mà còn đủ như là một khái niệm giải pháp. Đây là những trò chơi thuộc loại thông tin hoàn hảo hữu hạn; đó cũng là loại tổng bằng không (zero-sum). Trò chơi zero-sum (trong trường hợp một trò chơi chỉ có hai người chơi) là một trò chơi mà trong đó một người chơi chỉ có thể cải thiện lối chơi bằng cách làm cho người chơi khác chơi tồi hơn. Tic-tac-toe là một ví dụ giảm đơn về một trò chơi như vậy: bất cứ vận động nào đưa tôi đến gần với chiến thắng thì cũng đưa bạn gần đến với chiến bại, và ngược lại). Chúng ta có thể xác định xem một trò chơi có phải là một trò zero-sum không bằng cách xác định các hàm tiện ích của người chơi: trong trò chơi zero-sum các hàm này sẽ là những hình ảnh gương của một hàm khác, những kết quả ở thứ hạng cao của một người chơi lại là thứ hạng thấp đối với người kia và ngược lại. Trong một trò chơi như vậy, nếu tôi đang chơi một chiến lược như một chiến lược nhất định của bạn, tôi không thể làm được bất cứ điều gì tốt hơn, và nếu bạn cũng đang chơi một chiến lược như vậy thì vì bất cứ sự thay đổi chiến lược nào của tôi cũng sẽ phải làm cho bạn chơi tồi đi và ngược lại, kết quả là cuộc chơi của tôi có thể không có được giải pháp tương hợp với tính duy lý chung trừ tính cân bằng Nash duy nhất của nó. Chúng ta có thể đưa ra một tình huống khác: trong một trò chơi zero-sum tôi chơi một chiến lược mà chiến lược đó tối đa hóa cái khoản phải trả tối thiểu của tôi nếu bạn chơi tốt hết sức và hành động của bạn đồng thời làm nên cùng một kết quả, thì nó thực sự tương đương với toàn bộ chiến lược chơi tốt nhất của chúng ta, vì vậy cặp thủ tục “tối đa hóa” này được đảm bảo để phát hiện ra giải pháp duy nhất đối với trò chơi, đó là tính cân bằng Nash duy nhất của nó. (Trong trò chơi Tic-tac-toe thì như vậy là hòa. Bạn không thể làm gì tốt hơn hòa, cả tôi cũng không thể làm gì hơn, nếu cả hai chúng ta đều cố gắng chiến thắng và cố gắng để không bị thua).
Tuy nhiên hầu hết các trò chơi đều không có thuộc tính này. Trong một bài viết như thế này chúng ta không thể kê ra tất cả những cách thức mà các trò chơi có thể có vấn đề từ quan điểm của những giải pháp khả thể. (Có một vấn đề rất khác, đó là các lý thuyết gia đã phát hiện được toàn bộ những vấn đề khả thể!). Tuy nhiên, chúng ta cố gắng khái quát hóa các vấn đề một chút.
Trước tiên có một vấn đề là trong hầu hết các trò chơi phi-zero-sum số cân bằng Nash lớn hơn một, nhưng không phải tất cả mọi cân bằng Nash đều có vẻ hợp lý như những giải pháp mà các tay chơi duy lý sẽ chạm phải về phương diện chiến lược. Hãy xem xét trò chơi dạng chiến lược dưới đây (lấy ra từ Kreps 1990, trang 403):
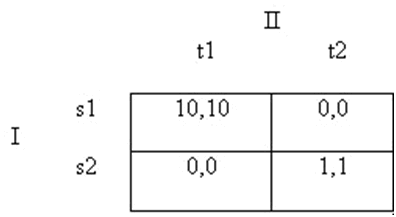
Hình 6
Trò chơi này có hai cân bằng Nash: s1-t1 và s2-t2. (Lưu ý rằng không phải các hàng và cột thống trị một cách nghiêm nhặt ở đây. Nhưng nếu người chơi I đang chơi s1 thì người chơi II có thể thực hiện không tốt hơn t1, và ngược lại; và tương tự như vậy đối với cặp s2-t2). Nếu cân bằng Nash là khái niệm giải pháp duy nhất của chúng ta thì chúng ta buộc phải nói rằng cả những kết quả này cũng có sức thuyết phục như một giải pháp vậy. Tuy nhiên nếu lý thuyết trò chơi được coi là một lý thuyết giải thích và/hoặc định chuẩn về sự suy lý chiến lược thì điều đó hình như là bỏ quên một cái gì đó: những người chơi duy lý chắc chắn có thông tin hoàn hảo sẽ hội tụ vào s1-t1? (Xin lưu ý rằng điều này không giống với tình huống trong trò chơi PD, trong đó tình huống cao hơn về phương diện xã hội là không thể đạt được vì đó không phải là một cân bằng Nash. Trong trường hợp trò chơi ở trên cả hai người chơi, mỗi người đều có một lý do để cố gắng hội tụ vào cân bằng Nash trong đó họ là những người chơi tốt hơn).
Điều này minh họa cho một sự thật là cân bằng Nash là một khái niệm giải pháp tương đối yếu (về mặt logic) thường không dự đoán trước được các giải pháp nhạy cảm về mặt trực giác vì nếu được áp dụng đơn độc thì nó sẽ không cho phép những người chơi sử dụng các nguyên tắc của lựa chọn cân bằng mà sự lựa chọn đó nếu không được yêu cầubằng tính duy lý thì ít nhất cũng không phải là phi lý. Hãy xem xét một ví dụ khác của Kreps (1990, trang 397):
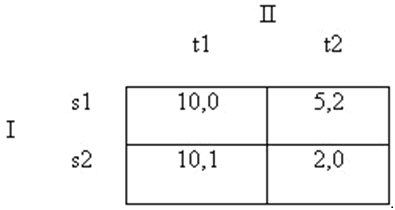
Hình 7
Trong trường hợp này không có chiến lược nào thống trị nghiêm nhặt một chiến lược khác. Tuy nhiên, hàng trên cùng của người chơi I, s1, thống trị yếu s2, vì người chơi I ít nhất cũng sử dụng s1 làm s2 vì bất cứ một phản ứng nào bởi người chơi số II, và về một phản ứng của người chơi số II (t2), thì số I thực hiện tốt hơn. Vì vậy phải chăng cả những người chơi lẫn người phân tích đều không nên xóa đi hàng số s2 bị thống trị yếu? Khi họ làm như vậy thì cột t1 được thống trị nghiêm nhặt, và cân bằng Nash s1-t2 được chọn là giải pháp duy nhất.
Tuy nhiên như Kreps đã tiếp tục chỉ rõ việc sử dụng ví dụ này, thì cái ý tưởng là các chiến lược thống trị nên được loại bỏ hệt như là những chiến lược nghiêm nhặt có những kết quả bổ sung. Hãy giả định chúng ta thay đổi các khoản phải trả của trò chơi chỉ một chút thôi như sau:
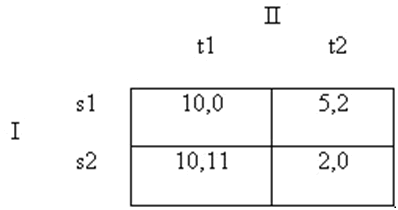
Hình 8
s2 vẫn bị thống trị yếu như trước; nhưng thuộc về 2 cân bằng Nash của chúng ta, s2 – t1 giờ đây là hấp dẫn nhất đối với cả hai người chơi; vậy thì tại sao các nhà phân tích lại muốn loại bỏ khả năng của nó? (Lưu ý rằng trò chơi này không sao chép lại logic của trò PD. Tại đó nó tạo ra ý nghĩa để loại bỏ cái kết quả hấp dẫn nhất, việc cùng từ chối nhận tội, vì cả hai người chơi đều có động cơ để đơn phương đi chệch hướng khỏi nó, vì vậy đó không phải là một cân bằng Nash. Đó không thực sự thuộc về s2-t1 của trò chơi này. Bạn nên bắt đầu nhận ra một cách rõ ràng tại sao chúng tôi lại gọi trò chơi PD là “không điển hình”). Lý lẽ cho việc loại bỏ các chiến lược thống trị yếu là ở chỗ người chơi I có thể nóng vội khi sợ rằng người chơi II không hoàn toàn chắc chắn là duy lý (hoặc người chơi II sợ rằng người chơi I không hoàn toàn duy lý, và cứ như thế cho đến vô cùng) và vì vậy có thể chơi t2 bằng một xác suất dương. Nếu khả năng xuất phát điểm từ tính duy lý được thực hiện một cách nghiêm nhặt thì chúng ta có một lý lẽ về việc loại bỏ các chiến lược thống trị yếu: vì vậy người chơi I tự đảm bảo cho cái kết quả thấp nhất của mình, s2-t2. Tất nhiên người đó phải trả giá cho sự đảm bảo này, bằng cách giảm khoản nhận được mong muốn từ 10 xuống 5. Một mặt chúng ta có thể hình dung rằng những người chơi có thể giao tiếp với nhau trước khi chơi, và đồng ý chơi các chiến lược tương quan sao cho có thể điều phối được s2-t1 bằng cách loại bỏ một số, hầu hết hoặc toàn bộ tính chất không chắc chắn nào tạo điều kiện cho việc loại bỏ hàng thống trị yếu s1, và thay vào đó, loại bỏ s1-t2 với tư cách là một cân bằng Nash vững chắc!
Bất cứ nguyên tắc nào được đề xuất cho việc giải quyết các trò chơi mà có tác động loại bỏ một hoặc nhiều cân bằng Nash khỏi sự xem xét thì đều được coi là bộ lọc của cân bằng Nash. Trong trường hợp vừa mới thảo luận thì việc loại bỏ các chiến lược thống trị yếu chính là một bộ lọc khả hữu vì nó lọc đi cân bằng Nash s2-t1, và tương quan là một cân bằng khác, vì thay vào đó nó lọc cân bằng Nash khác s2-t1. Vậy thì bộ lọc nào thích hợp với tư cách là một khái niệm giải pháp? Những ai nghĩ về lý thuyết trò chơi như một lý thuyết định chuẩn và/hoặc giải thích có tính duy lý chiến lược thì đều tạo ra một văn liệu bản chất trong đó những ưu khuyết điểm của một số lượng lớn các bộ lọc đều cần phải bàn thêm. Về nguyên tắc dường như không có giới hạn đối với số bộ lọc là cái có thể được xem xét, vì có thể cũng không có giới hạn về tập trực giác triết học về những nguyên tắc nào mà một tác nhân duy lý có thể hoặc không thể nhận thấy là thích hợp để theo hoặc để e ngại, hoặc hy vọng rằng những người chơi khác đang theo.
Các nhà hành vi luận bảo lưu một quan điểm rất mơ hồ về hành động này. Họ coi công việc của lý thuyết trò chơi là để tiên đoán các kết quả đem đến một sự phân phối nào đó về những sắp xếp chiến lược và một sự phân phối nào đó về những mong muốn liên quan đến những sắp xếp chiến lược của những người khác, là những thứ được tạo nên bởi những quá trình thể chế và/hoặc sự lựa chọn tiến hóa (xem phần 7 để thảo luận thêm). Về quan điểm các cân bằng Nash có thể tồn tại vững chắc trong một trò chơi có thể được xác định bằng những động thái cơ sở là thứ trang bị cho những người chơi với những sắp xếp tiên thiên đối với một trò chơi. Các bản chất chiến lược của người chơi vì vậy được đối xử như một tập đầu vào ngoại sinh cho trò chơi, hệt như những hàm tiện ích vậy. Vì vậy các nhà hành vi luận nghiêng về phía tìm kiếm những bộ lọc chung của bản thân khái niệm cân bằng chí ít cũng đến mức mà những bộ lọc này tham gia vào việc xây dựng mô hình của những thể hiện duy lý tính tinh vi hơn đối với việc kiên định tối đa hóa tiện ích. Các nhà hành vi luận thường nghiêng về phía nghi ngờ rằng mục đích của việc tìm kiếm một lý thuyết tổng quát của tính duy lý tạo nên ý nghĩa như một dự án. Các thể chế và các quá trình tiến hóa xây dựng nhiều môi trường và cái được coi là một thủ tục duy lý trong một môi trường có thể lại không được ưa thích trong một môi trường khác. Tính duy lý kinh tế chỉ đòi hỏi rằng các tác nhân có những sở thích ổn định, tức là những sở thích không ưu tiên a hơn b và b hơn c và c hơn a. Một trong những sự sắp xếp chiến lược lớn tương hợp với yêu cầu tối thiểu này và các quá trình tiến hóa hoặc thể chế có thể tạo ra những trò chơi trong bất cứ quá trình nào của chúng. Về phương diện này thì các cân bằng Nash là một khái niệm cân bằng vững chắc vì nếu những người chơi phát triển những chiến lược trong các môi trường cạnh tranh, là những môi trường mà những ai không thực hiện những chiến lược tối ưu nhất định của những người khác trong môi trường riêng biệt đó sẽ bị bật khỏi quá trình cạnh tranh và sự lựa chọn như vậy cũng sẽ loại bỏ chúng hoặc cổ vũ việc tìm hiểu những sắp xếp mới. Không có nhiều khái niệm duy lý “được lọc” có thể quan niệm là thật nói chung; và vậy là theo các nhà hành vi luận những bộ lọc Nash dựa trên các bộ lọc của tính duy lý cũng có vẻ như thuộc về mối quan tâm tình cờ.
Điều này không có nghĩa là các nhà hành vi luận tuyên bố từ bỏ mọi cách giới hạn các tập cân bằng Nash vào các tập con hợp lý. Đặc biệt họ định thông cảm với những cách tiếp cận thay đổi trung tâm điểm từ bản thân tính duy lý sang những mối quan tâm về các động thái thông tin của các trò chơi. Có lẽ chúng ta không có gì phải ngạc nhiên là phân tích cân bằng Nash tự thân nó thường thất bại không thể nói được gì nhiều cho chúng ta về mối quan tâm đến các trò chơi dạng chiến lược (chẳng hạn Hình. 6 ở trên), trong đó cấu trúc thông tin bị chặn. Những vấn đề lựa chọn cân bằng thường được thể hiện một cách hiệu quả trong bối cảnh các trò chơi dạng mở rộng.
2.6. Tính duy lý đơn nguyên và Sự hoàn hảo của trò chơi phụ
Để làm sâu sắc hơn nữa hiểu biết của chúng ta về các trò chơi dạng mở rộng, chúng ta cần một ví dụ với một cấu trúc thú vị hơn là cái mà trò chơi PD đưa ra.
Hãy xem xét trò chơi được mô tả theo hình cây dưới đây:
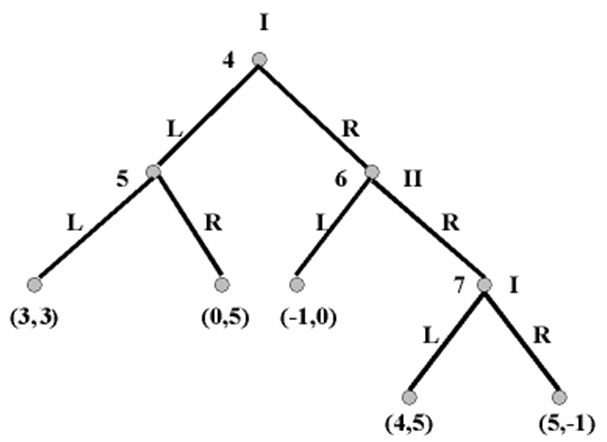
Hình 9
Trò chơi này không nhằm làm tương hợp với một tình huống bất kỳ tiền nhận thức nào đó; nó đơn giản là một đối tượng toán tìm cách để ứng dụng. (L và R ở đây chỉ xác định “trái” và “phải” tương ứng).
Bây giờ chúng ta hãy xem xét dạng chiến lược của trò chơi này:
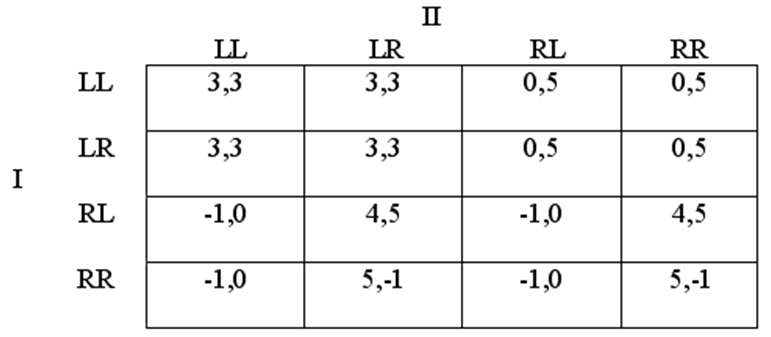
Hình 10
(Nếu bạn bị bối rối với ma trận này thì chỉ cần nhớ rằng một chiến lược cần phải nói cho người chơi phải làm gì ở mỗi tập thông tin mà trong đó người chơi thực hiện một hành động. Vì mỗi người chơi lựa chọn giữa hai hành động ở hai tập thông tin một, nên tổng cộng mỗi người chơi có 4 chiến lược. Chữ cái thứ nhất trong mỗi thiết kế chiến lược nói với mỗi người chơi cái mà họ phải làm nếu họ có được tập thông tin đầu tiên của mình, thứ hai là cái mà họ phải làm khi họ có được tập thông tin thứ hai. I.e., LR đối với người chơi II nói với II phải chơi L nếu có được tập thông tin 5, và chơi R nếu có được tập thông tin 6). Nếu bạn xem xét kỹ ma trận này bạn sẽ phát hiện ra rằng (LL, RL) là nằm trong số các cân bằng Nash. Trong trường hợp này có một chút rắc rối, bởi vì nếu người chơi I có được tập thông tin (7) trong trò chơi dạng mở rộng thì tôi sẽ khó lòng mà mong muốn chơi L ở đó; người đó thu được một khoản được trả cao hơn bằng cách chơi ở nút 7. Phép phân tích cân bằng Nash duy nhất không lưu ý đến điều này vì cân bằng Nash khuyến khích cái xảy ra bên ngoài đường dẫn của trò chơi. Người chơi I khi chọn L ở nút 4 đảm bảo rằng sẽ tới được nút 7; điều đó có nghĩa là đó là “bên ngoài quĩ đạo chơi”. Tuy nhiên khi phân tích các trò chơi dạng mở rộng chúng ta xem cái gì sẽ xảy ra bên ngoài đường dẫn của trò chơi, vì công việc xem xét này là có tính quyết định đối với cái xảy ra trong đường dẫn của trò chơi. Chẳng hạn sự thật là người chơi I sẽ chơi R nếu tới được nút 7, làm cho người chơi II chơi L nếu đến được nút 6, và đó chính là lý do tại sao người chơi I sẽ không chọn R ở nút 4. Chúng ta đang vứt bỏ lượng thông tin liên quan đến các giải pháp trò chơi nếu chúng ta bỏ qua những sản phẩm bên ngoài đường dẫn khi phân tích cân bằng Nash thuần túy đã làm. Cần lưu ý rằng lý do để nghi ngờ rằng cân bằng Nash không phải là một khái niệm cân bằng tổng thể hoàn toàn thỏa đáng, tự thân đã không liên quan gì đến các trực giác về lý tính như trong trường hợp các khái niệm bộ lọc đã được thảo luận ở phần 2.5.
Giờ đây hãy áp dụng thuật toán Zermelo vào loại hình tăng cường của ví dụ hiện thời của chúng ta. Chúng ta lại bắt đầu với trò chơi phụ cuối cùng, trò chơi đi xuống từ nút 7. Đây là vận động của người chơi I, và người đó chọn R vì thích khoản được trả của mình là 5 so với được trả 4 mà cô/anh ta nhận được bằng cách chơi L. Vì vậy chúng ta chỉ định khoản được trả (5, -1) cho nút 7. Vậy là ở nút 6 người chơi II đối mặt với lựa chọn giữa (-1, 0) và (5, -1). Người đó chọn L. Tại nút 5, người chơi II chọn R. Vậy thì tại nút 4 người chơi I chọn lựa chọn giữa (0, 5) và (-1, 0), và vì vậy mà chơi L. Nên nhớ rằng vì trong trò chơi PD, một kết quả xuất hiện ở một nút đầu cuối – (4, 5) từ nút 7 – đó là cân bằng Pareto cao hơn các cân bằng Nash. Hơn nữa, tuy nhiên, các động thái của trò chơi ngăn cản nó không tới được.
Sự thật là thuật toán Zermelo đã chọn lựa vector chiến lược (LR, RL) như là giải pháp duy nhất cho trò chơi đã cho thấy rằng nó đạt được một cái gì đó khác nữa chứ không phải chỉ là một cân bằng Nash. Trong thực tế thì nó đang tạo ra sự cân bằng hoàn hảo của trò chơi phụ (SPE – supgame perfect equilibrium). Nó đưa đến một kết quả đạt được cân bằng Nash không chỉ trong toàn bộ trò chơi mà còn cả trong mỗi trò chơi phụ nữa. Đây là một khái niệm giải pháp có sức thuyết phục vì không giống với những bộ lọc của phần 2.5, nó không đòi hỏi “nhiều” tính duy lý của các tác nhân, mà đòi hỏi ít hơn. (Tuy nhiên người ta cho rằng những người chơi không chỉ biết mọi thứ về phương diện chiến lược liên quan đến tình trạng của họ, mà còn sử dụng tất cả các thông tin đó; chúng ta phải cẩn thận để không lẫn lộn tính duy lý với khả năng tính toán). Các tác nhân ở mỗi nút chỉ đơn giản lựa chọn đường dẫn nào đem đến cho họ khoản được trả cao nhất trong trò chơi phụ bắt nguồn từ nút đó; và sau đó khi giải quyết cuộc chơi, họ thấy trước rằng họ sẽ thực hiện tất cả những cái đó. Các tác nhân vượt lên theo cách này được gọi là đơn nguyên duy lý, có nghĩa là duy lý ngắn hạn ở mỗi bước. Họ không tự tưởng tượng, bằng một trí tưởng tượng nào đó các quá trình siêu duy lý tính khi tác động trở lại đối với những sở thích cục bộ vì mục đích của một mục tiêu rộng lớn hơn nào đó. Nên nhớ rằng như trong trò chơi PD, điều này có thể dẫn đến các kết quả đáng tiếc về phương diện xã hội. Trong ví dụ hiện thời của chúng ta, người chơi I là tốt hơn, người chơi II không tồi hơn, ở nút bên tay trái xuất phát từ nút 7 so với kết quả ở SPE (cân bằng hoàn hảo của trò chơi phụ). Nhưng tính duy lý rất đơn nguyên của người chơi I và nhận thức của người chơi II về vấn đề đó đã đóng kín kết quả hữu hiệu về phương diện xã hội. Nếu những người chơi của chúng ta muốn làm xuất hiện kết quả có tính cân bằng hơn (4,5) thì họ phải làm như vậy bằng cách tái thiết kế các thể chế của mình sao cho có thể thay đổi được cấu trúc của các trò chơi mà họ thực hiện. Chỉ mong rằng họ có thể là siêu duy lý theo cái cách thức dường như không gắn kết chặt chẽ như một cách tiếp cận.
2.7. Tính chất đạo đức và Hiệu quả trong các Trò chơi
Nhiều người đọc có thể cho rằng kết luận của phần trước đã được thực hiện dựa trên cơ sở không phòng thủ đầy đủ. Chắc chắn là những người chơi có thể chỉ thấy rằng kết quả (4,5) là cao hơn về phương diện xã hội và đạo đức; và vì vậy chúng ta biết họ có thể cũng thấy đường dẫn của các hành động dẫn đến nó, vậy ai là lý thuyết gia trò chơi để tuyên bố về điều đó trong cái trò chơi mà họ đang chơi, nó phải chăng là không đạt được? Thực tế thì việc gợi ý rằng tính siêu duy lý là một ý chí của người chơi là có tính định hướng về phương diện triết học mặc dù nó thực sự là cái mà các nhà hành vi luận về lý thuyết trò chơi tin tưởng. Người đọc nào tìm kiếm một sự biện minh triệt để cho niềm tin này thì đều được qui vào Binmore (1994,1998). Tuy nhiên trước khi chúng ta rời khỏi những vấn đề ở một điểm có tác dụng làm cân bằng (tại đây), chúng ta cần phải cẩn thận để không lẫn lộn cái vấn đề đang còn tranh cãi với những kết quả của một nhầm lẫn kỹ thuật đơn giản. Chúng ta hãy cùng xem lại nan đề người tù. Chúng ta đã thấy rằng trong cân bằng Nash duy nhất về trò chơi PD, cả hai tay chơi đều nhận được ít tiện ích hơn họ có thể nhận được thông qua sự hợp tác chung với nhau. Điều này có thể tác động mạnh đến bạn (hệt như nó đã tác động đến nhiều nhà bình luận) như là một sự éo le. Chắc chắn bạn có thể nghĩ rằng nó đơn giản nảy sinh từ một sự kết hợp của tính ích kỷ và bệnh hoang tưởng về phía những tay chơi. Ngay từ đầu họ đã không quan tâm đến thiện chí về phương diện xã hội và sau đó họ đã tự bắn vào chân mình bằng cách không đáng để tôn trọng các thỏa thuận.
Cách tư duy như vậy đã dẫn đến những hiểu lầm tai hại về lý thuyết trò chơi, và vì vậy những cách hiểu đó phải được loại bỏ. Trước hết chúng tôi xin phép giới thiệu một vài thuật ngữ để nói về các kết quả. Các nhà kinh tế học phúc lợi đo lường một cách điển hình hàng hóa xã hội bằng khuôn khổ hiệu xuất Pareto. Một phân phối tiện ích o thì được gọi là ưu thế Pareto đối với phân phối d chỉ trong trường hợp từ trạng thái d có một tái phân phối tiện ích cho o chẳng hạn như tối thiểu là một tay chơi chơi kém. Thất bại trong việc chuyển thành một tái phân phối ưu thế Pareto là thiếu hiệu quả vì sự tồn tại của o như một khả năng logic chỉ rõ rằng trong d một tiện ích nào đó đang bị bỏ phí. Vậy là kết quả (3,3) thể hiện sự cộng tác chung trong mô hình của chúng ta về trò chơi PD rõ ràng là ưu thế Pareto đối với sự phản bội chung; ở (3,3) cả hai tay chơi đều thành công hơn ở (2,2). Vì vậy sẽ là chân khi trò chơi PDs dẫn đến các kết quả thiếu hiệu quả. Đó cũng là chân đối với ví dụ của chúng ta trong phần 2.6.
Tuy nhiên, tính thiếu hiệu quả không nên đi kèm với tính chất phi đạo đức. Một hàm tiện ích đối với một tay chơi được giả định thể hiện bất cứ cái gì mà tay chơi quan tâm đến, đó có thể là bất cứ thứ gì. Như chúng tôi đã mô tả tình huống hai người tù của chúng ta, họ thực sự chỉ quan tâm đến bản án tù riêng đối với họ, nhưng lại không có cái gì là cốt yếu trong vấn đề này. Cái làm cho một cuộc chơi trở thành một ví dụ về trò chơi PD thì duy nhất chỉ là cấu trúc khoản phải trả của nó. Vì vậy chúng ta có thể có hai kiểu loại Mẹ Theresa ở đây, mà cả hai đều ít quan tâm đến bản thân mình mà chỉ mong được chăm sóc lũ trẻ đói khổ. Nhưng hãy hình dung là Mẹ Theresa thật mong muốn được chăm bọn trẻ ở Calcutta trong khi Mẹ Juanita lại muốn chăm sóc bọn trẻ ở Bogota. Và hãy hình dung là cơ quan trợ giúp quốc tế sẽ tối đa hóa khoản quyên góp của mình nếu hai vị thánh nữ đó nhắm đến cùng một thành phố; sẽ cho một khoản quyên góp cao thứ nhì nếu mỗi người nhắm đến thành phố của người kia; và khoản quyên góp thấp nhất nếu mỗi người đều nhắm đến thành phố riêng của mình. Trong trường hợp này các thánh nữ của chúng ta đang tham gia một trò chơi PD, mặc dù quá vị kỷ hoặc không bận tâm đến vấn đề xã hội.
Quay trở lại với người tù của chúng ta, hãy giả định rằng ngược lại với những định đề của chúng ta họ tạo ra giá trị cho tình trạng hạnh phúc của mỗi người cũng như cho riêng bản thân họ. Trong trường hợp này, điều đó phải được phản ánh trong các hàm tiện ích của họ, và vì vậy mà cả trong khoản nhận được của họ nữa. Nếu cấu trúc khoản nhận được của họ thay đổi thì họ sẽ không còn tham gia trò chơi nữa. Nhưng tất cả những cái đó đều chỉ ra rằng không phải mỗi tình huống khả thể đều là một trò chơi PD; nó không chỉ rõ rằng mối đe dọa của các kết quả thiếu hiệu quả là một sản phẩm đặc biệt của tính vị kỷ. Nó là logic của tình huống người tù chứ không phải là tâm lý của họ, nó đánh bẫy họ trong cái kết quả không hiệu quả, và nếu nó thực sự là tình huống của họ thì họ đang bị mắc kẹt trong đó (trừ những phức tạp hơn sẽ được thảo luận ở dưới đây). Các tác nhân muốn tránh những kết quả không hiệu quả nên ngăn chặn sự xuất hiện của bất cứ trò chơi nào; người phòng vệ của khả năng siêu duy lý thực sự giả định rằng họ cố gắng tự thân phát hiện những trò chơi như vậy bằng cách tự họ biến thành những loại tác nhân khác.
Vậy là nhìn chung một trò chơi được định nghiã một cách cục bộ bằng khoản phải trả được ấn định cho những tay chơi. Nếu một giải pháp được đề xuất liên quan đến sự thay đổi ngầm những khoản phải trả ấy thì “giải pháp” này thực sự là một cách trá hình để thay đổi chủ thể.
2.8. Những bàn tay run
Vấn đề vừa rồi của chúng ta ở trên mở ra cách thức cho một vấn đề rắc rối triết học vẫn cuốn hút sự chú ý đối với các nền tảng logic về lý thuyết trò chơi. Nó có thể được nêu ra liên quan đến bất cứ số lượng ví dụ nào, nhưng chúng ta sẽ mượn một người tao nhã từ C. Bicchieri (1993) đã đưa ra một cách xử lý tăng cường vấn đề được phát hiện trong các văn liệu. Hãy xem xét trò chơi sau:
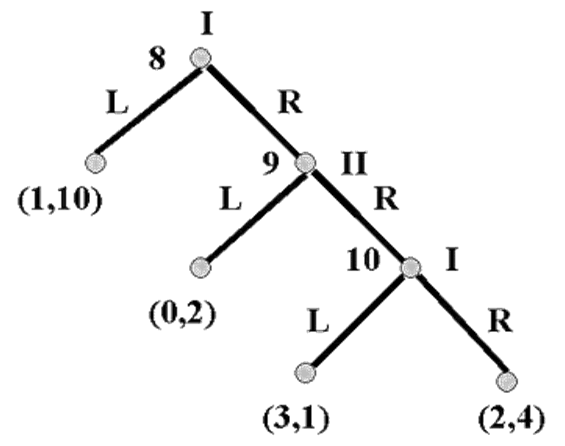
Hình 11
Kết quả cân bằng Nash ở đây thuộc nút đơn xa nhất bên trái từ nút 8 nghiêng xuống. Hãy xem nút này, lại một qui nạp ngược. Tại nút 10, tay chơi I sẽ đánh L để nhận khoản được trả là 3, cho tay chơi II khoản được trả là 1. Tay chơi II có thể làm tốt hơn bằng cách chơi L ở nút 9, cho tay chơi I khoản nhận được là 0. Có một vấn đề khó xử được Bicchieri nêu lên [cùng các tác giả khác, bao gồm Binmore [1987] và Pettit & Sugden [1989] bằng cách suy luận sau. Tay chơi I có thể làm tốt hơn bằng cách chơi L ở nút 8; vậy thì đó chính là điều mà tay chơi I làm và trò chơi kết thúc mà không có tay chơi II tham gia chơi tiếp. Nhưng lúc này hãy lưu ý đến sự suy lý cần thiết để hỗ trợ cho sự tiên đoán này. Tay chơi I chơi L ở nút 8 vì cô/anh ta biết rằng tay chơi II là người duy lý, và vì vậy sẽ chơi L ở nút 9 vì tay chơi II biết rằng tay chơi I là người duy lý và vì vậy sẽ chơi L ở nút 10. Nhưng chúng ta lại thấy xuất hiện một nghịch lý tiếp theo tay chơi I phải cho rằng tay chơi II ở nút 9 sẽ tiên đoán là việc chơi duy lý của I sẽ ở nút 10 mặc dù đã đến một nút (9) là nút chỉ có thể đến được nếu tay chơi I không duy lý! Nếu tay chơi I không duy lý thì tay chơi II sẽ không được thanh minh bằng cách tiên đoán rằng tay chơi I sẽ không chơi R ở nút 10, trong trường hợp này thì không rõ là tay chơi II sẽ không chơi R ở nút 9; và nếu tay chơi II chơi R ở nút 9 thì tay chơi I sẽ có một khoản nhận được tốt hơn sau đó cô/anh ta nhận được nếu cô/anh ta chơi L ở nút 8. Cả hai tay chơi phải sử dụng lối qui nạp ngược đòi hỏi rằng tay chơi I biết rằng tay chơi II biết tay chơi I là duy lý; nhưng tay chơi II chỉ có thể giải quyết được cuộc chơi bằng cách sử dụng cái lý lẽ qui nạp ngược là cái lấy tính phi lý của tay chơi I làm một tiên đề. Đó chính là nghịch lý của cách qui nạp ngược.
Có một cách chuẩn mực nhất để hiểu được nghịch lý này là viện đến cái gọi là “bàn tay run” theo Selten [1975]. Tư tưởng này cho rằng một quyết định và hành động hợp lý có thể “tách ra” khỏi xác suất phi-zero tuy nhỏ. Thế có nghĩa là một tay chơi có thể muốn thực hiện một hành động nhưng vì mắc lỗi trong khi thực hiện và thay vào đó đã đưa trò chơi xuống theo một đường dẫn nào đó khác. Nếu thậm chí chỉ có một chút khả năng một tay chơi có thể mắc lỗi – đó là “bàn tay” cô/anh ta “có thể run” thì không có mâu thuẫn nào được đưa vào bởi một tay chơi sử dụng một lý lẽ qui nạp ngược yêu cầu một giả định đề rằng một tay chơi khác đã chiếm đường dẫn mà một tay chơi duy lý có thể không lựa chọn. Trong ví dụ của chúng ta tay chơi II có thể suy lý về cái cần làm ở nút 9 phụ thuộc vào định đề cho rằng tay chơi I chọn L ở nút 8, nhưng sau đó đã bị thất bại.
Có một văn liệu kỹ thuật cơ bản về cái nghịch lý qui nạp ngược đó mà nguồn tổng hợp có thể tìm được ở Bicchieri (1993). (Cần lưu ý là Bicchieri không tán thành viện lẽ vào những bàn tay run như một giải pháp thích hợp. Tuy nhiên việc thảo luận về đề xuất riêng của bà ở đây có lẽ đã làm cho chúng ta đi quá xa vào những tính chất kỹ thuật. Người đọc nào chú ý nên nghiên cứu cuốn sách của bà). Thách đố được giới thiệu ở đây chỉ để xác định rằng những bộ lọc thuộc loại đã được thảo luận trong phần 2.6 có thể được cổ vũ nhiều hơn là những trực giác thuần túy về khái niệm tính duy lý. Vì nếu những bàn tay có thể run thì những người chơi thuần túy duy lý sẽ có động cơ để lo lắng về những xác xuất mà với nó những xuất phát điểm hiển nhiên từ trò chơi duy lý sẽ được nhận thấy. Chẳng hạn nếu bàn tay đối thủ của tôi có thể run, thì bàn tay ấy sẽ cho tôi lý do chính đáng để tránh cái chiến lược thống trị yếu s2 trong ví dụ thứ ba của phần 2.5. Hơn nữa đối thủ của tôi có thể cam kết chơi t1 trong trò chơi đó và tôi có thể tin vào lời hứa của anh ta. Nhưng nếu bàn tay của anh ta sau đó cũng run và kết quả là anh ta sẽ chơi t2, thì tôi phải nhận một khoản nhận được tồi nhất. Nếu tôi đảo ngược rủi ro thì trong tình huống như vậy dường như tôi có thể gắn với những chiến lược thống trị yếu.
Nghịch lý qui nạp ngược, giống như những câu đố đưa ra bởi bộ lọc cân bằng chủ yếu là một vấn đề cho những ai coi lý thuyết trò chơi như một đóng góp cho một lý thuyết định chuẩn của tính duy lý (đặc biệt là đóng góp cho lý thuyết lớn, lý thuyết duy lý chiến lược). Nhà hành vi luận có thể đưa ra một loại lý giải khác về lối chơi rõ ràng là phi lý và sự thận trọng mà nó cổ vũ. Điều này liên quan đến việc viện vào một sự kiện kinh nghiệm chủ nghĩa là các tác nhân thực sự gồm cả những con người phải học những chiến lược cân bằng của các trò chơi mà họ tham gia, chí ít là bất cứ khi nào những trò chơi đó rơi vào hoàn cảnh hoàn toàn phức tạp. Công việc nghiên cứu đã chỉ ra rằng ngay cả một trò chơi đơn giản như trò Nan đề Người tù cũng đòi hỏi người ta phải học [Ledyard 1995, Sally 1995, Camerer 2003, tr.265]. Ý nghĩa của việc nói rằng con người cần phải học những chiến lược cân bằng là ở chỗ chúng ta phải có đôi chút phức tạp hơn là cái đã được chỉ ra ở phần trước trong việc tạo ra các hàm tiện ích từ hành vi trong việc áp dụng Lý thuyết Bộc lộ Sở thích (Revealed Preference Theory). Thay cho việc cấu tạo các hàm tiện ích dựa trên cơ sở những tình tiết đơn, chúng ta phải làm như vậy trên cơ sở của những hành vi quan sát được khi nó đã ổn định, bằng cách biểu thị độ chín của việc học đối với các chủ thể được đặt vấn đề và cái trò chơi được đặt vấn đề. Một lần nữa cần phải nói rằng Nan đề Người tù cho ta một ví dụ rất tốt. Mọi người đều phải đối mặt với một số Nan đề Người tù chí ít là một lần trong cuộc sống hàng ngày, nhưng họ phải đối mặt với nhiều trò chơi PD lặp đi lặp lại với những người không xa lạ. Kết quả là khi bắt đầu cái định làm như một trò chơi PD một lần duy nhất trong đời trong phòng thực nghiệm ngay từ đầu người ta đã có ý định chơi cứ như là trò chơi ấy là một vòng đơn của một trò chơi PD lặp đi lặp lại. Trò PD lặp đi lặp lại đó có nhiều cân bằng Nash là cái liên quan đến sự hợp tác hơn là đảo ngũ. Vì vậy các chủ thể kinh nghiệm có ý định hợp tác đầu tiên trong các hoàn cảnh này, nhưng lại học sau khi một số vòng chơi bị thất bại. Người thực nghiệm có thể suy luận rằng cô ta đã qui nạp một cách thành công một cuộc chơi PD một lần duy nhất với cơ cấu thực nghiệm cho đến khi cô ta thấy hành vi này đã ổn định. (Như đã lưu ý ở phần 2.7 ở trên, nếu nó không ổn định như vậy thì cô ta phải suy luận rằng cô ta đã thất bại trong việc qui nạp trò chơi PD một lần duy nhất và các chủ thể của cô ta đang chơi một trò chơi nào đó khác).
Nghịch lý qui nạp ngược giờ đây đã bị hủy bỏ. Trừ khi các tay chơi đã trải nghiệm lối chơi cân bằng với một tay chơi khác trong quá khứ, ngay cả khi tất cả họ đều duy lý và tất cả đều tin tưởng nhau thì chúng ta sẽ tiên đoán rằng họ sẽ gắn một xác suất dương nào đó vào việc phỏng đoán rằng các bên tương tác đã không tìm hiểu để biết được toàn bộ các cân bằng. Vậy là điều này lý giải tạo sao các tác nhân duy lý trừ khi họ thích mạo hiểm, lại có thể chơi cứ như là họ tin vào những bàn tay run vậy.
Việc tìm hiểu các cân bằng bởi các tác nhân duy lý có thể có nhiều dạng khác nhau đối với những tác nhân khác nhau và đối với những trò chơi ở những cấp độ phức tạp và rủi ro khác nhau. Vì vậy việc tích hợp nó vào các mô hình lý thuyết trò chơi của các tương tác sẽ giới thiệu một tập kỹ thuật tính mở rộng mới. Vì lý thuyết tổng quát này đã được phát triển đầy đủ nhất nên người đọc có thể tham khảo [Fudenberg and Levine 1998].
3. Tính không chắc chắn, Rủi ro và những Cân bằng rãy
Các trò chơi mà chúng ta xây dựng mô hình cho vấn đề này toàn bộ đều liên quan đến các tay chơi bằng cách chọn lựa một trong số các chiến lược thuần túy, trong đó mỗi người đều tìm kiếm một quá trình hành động tối ưu riêng ở mỗi nút tạo nên một phản ứng tốt nhất đối với những hành động của những tay chơi khác. Tuy nhiên thường xuyên một tiện ích của một tay chơi được tối ưu hóa thông qua việc sử dụng một chiến lược hỗn hợp, trong đó cô ta gieo một đồng xu trong số một vài hành động khả thể khác. (Sau đây chúng ta sẽ thấy có một sự lý giải thay thế đặc biệt hỗn hợp không liên quan đến sự ngẫu nhiên hóa ở một tập thông tin đặc biệt; nhưng chúng ta sẽ bắt đầu ở đây từ việc lý giải hành động gieo đồng tiền và sau đó sẽ dựa vào nó ở phần 3.1). Hòa trộn là cần thiết bất cứ khi nào không có một chiến lược thuần túy tối đa hóa tiện ích của người chơi dựa vào toàn bộ các chiến lược của đối phương. Trò chơi qua sông từ phần 1 của chúng ta đã minh họa cho vấn đề này. Như chúng ta đã thấy, thách thức trong trò chơi này bao gồm sự thật là nếu sự suy lý của người chạy trốn lựa chọn một chiếc cầu đặc biệt với tư cách là một lựa chọn tối ưu, thì người săn đuổi anh ta phải được giả định là có thể để nhân lên cái suy lý đó. Vậy là người chạy trốn có thể thoát được chỉ khi người theo đuổi anh ta không thể tiên đoán một cách chắc chắn rằng anh ta sẽ sử dụng chiếc cầu nào. Tính chất đối xứng của năng lực suy lý về phần hai tay chơi đảm bảo rằng người chạy trốn có thể làm cho người săn đuổi bất ngờ chỉ khi nào anh ta làm cho chính mình bất ngờ.
Hãy giả sử rằng chúng ta lờ đi những tảng đá và lũ rắn trong một chốc lát và tưởng tượng rằng những chiếc cầu kia là hoàn toàn an toàn. Cũng có thể giả định rằng người chạy trốn không có hiểu biết đặc biệt nào về người săn đuổi anh ta làm cho anh ta liều lĩnh thử thách một sự phân phối xác suất phỏng đoán đặc biệt đối với các chiến lược có sẵn của người săn đuổi.
Trong trường hợp này, cách cư xử tốt nhất của người chạy trốn là gieo con súc sắc ba mặt trong đó mỗi mặt đều thể hiện một chiếc cầu khác nhau (hoặc truyền thống hơn, một con súc sắc 6 mặt trong đó mỗi chiếc cầu thể hiện bởi hai mặt). Sau đó anh ta phải tự cam kết trước việc sử dụng bất cứ chiếc cầu nào được lựa chọn bằng lựa chọn ngẫu nhiên này. Công việc này ấn định tần số xuất hiện khả năng sống của anh ta bất chấp người săn đuổi anh ta làm gì; nhưng vì người săn đuổi không có bất cứ lý do gì để ưa thích bất cứ chiến lược hỗn hợp hay đơn lẻ nào có sẵn, và vì trong bất cứ trường hợp nào thì chúng ta cũng đang đoán chừng cái tình huống hiểu biết của cô ta là cân bằng với cái tình huống của người chạy trốn, thì chúng ta có thể giả định rằng cô ta sẽ gieo con súc sắc ba mặt của riêng mình. Giờ đây người chạy trốn có một xác suất trốn thoát là 2/3 và xác xuất của người săn đuổi là 1/3 khả năng bắt được anh ta. Người chạy trốn không thể cải thiện được tình hình dựa vào tỷ lệ xuất hiện khả năng sống còn nếu người săn đuổi là người duy lý, vì vậy cả hai chiến lược ngẫu nhiên đều có trong cân bằng Nash.
Bây giờ thì chúng tôi xin giới thiệu lại những yếu tố tham số, có nghĩa là những tảng đá rơi ở cây cầu #2 và những con rắn hổ mang ở cây cầu #3. Hơn nữa hãy giả định rằng người chạy trốn chắc chắn được an toàn qua chiếc cầu #1, có một tỷ lệ là 90% qua chiếc cầu số #2, và 80% qua cầu số #3. Chúng ta có thể giải quyết trò chơi mới này nếu chúng ta có những định đề chắc chắn về các hàm tiện ích của hai tay chơi. Hãy giả định rằng tay chơi I, người chạy trốn chỉ quan tâm đến sống hoặc chết (thích sống hơn chết) trong khi người săn đuổi chỉ đơn giản muốn báo cáo rằng người chạy trốn đã chết vì cô ta thích báo cáo như vậy hơn là báo cáo anh ta đã chạy thoát. (Nói cách khác, cô ta không quan tâm đến việc người chạy trốn sống hay chết như thế nào). Trong trường hợp này người chạy trốn chỉ đơn giản lựa chọn các công thức ngẫu nhiên hóa và so sánh nó theo những cấp độ khác nhau của sự nguy hiểm mang tính tham số ở ba chiếc cầu. Cần phải nghĩ rằng mỗi chiếc cầu là một điều may rủi đối với các kết quả khả thể của người chạy trốn, trong đó mỗi may rủi có một khoản phải trả mong muốn trong khuôn khổ của những hạng mục trong hàm tiện ích của ông ta.
Hãy xem xét vấn đề từ quan điểm của người săn đuổi. Cô ta sẽ sử dụng chiến lược cân bằng Nash của mình khi cô ta lựa chọn sự hỗn hợp của các xác suất đối với ba chiếc cầu, và nó làm cho người chạy trốn trở nên trung lập giữa các chiến lược khả thể thuần túy của anh ta. Chiếc cầu có những tảng đá thì 1.1 lần nguy hiểm đối với anh ta hơn là chiếc cầu an toàn. Vì vậy anh ta sẽ trung lập giữa hai chiếc cầu trong khi người săn đuổi thì 1.1 lần thích đợi tại chiếc cầu an toàn hơn là chiếc cầu có đá rơi. Cầu có rắn thì 1.2 lần nguy hiểm đối với người chạy trốn hơn là chiếc cầu an toàn. Vì vậy anh ta sẽ trung lập trong việc lựa chọn giữa hai chiếc cầu này khi xác suất đợi của người săn đuổi ở chiếc cầu an toàn là 1.2 lần cao hơn xác suất đợi của chính cô ta ở chiếc cầu có rắn. Hãy giả sử chúng ta sử dụng s1, s2 và s3 để thể hiện các tỷ lệ sống sót tham số của người chạy trốn ở mỗi chiếc cầu. Vậy là người săn đuổi tối đa hóa tỷ lệ sống sót ròng qua bất cứ cặp cầu nào bằng cách điều chỉnh các xác suất p1 và p2 là những xác suất mà cô ta sẽ chờ đợi sao cho
s1 (1 − p1) = s2 (1 − p2)
vì p1 + p2 = 1, nên chúng ta có thể viết lại công thức này là
s1 x p2 = s2 x p1
vì vậy
p1/s1 = p2/s2.
Cuối cùng người săn đuổi phát hiện ra chiến lược cân bằng Nash của cô ta bằng cách giải các phương trình sau:
1 (1 − p1)
=
0.9 (1 − p2)
=
0.8 (1 − p3)
p1 + p2 + p3 = 1.
Vậy thì
p1
=
49/121
p2
=
41/121
p3
=
31/121
p1
=
p2
=
p3
=
Bây giờ hãy để f1, f2, f3 thể hiện các xác suất với những xác suất mà người chạy trốn chọn lựa mỗi chiếc cầu tương ứng. Vậy là người chạy trốn phát hiện ra chiến lược cân bằng Nash của anh ta bằng cách giải:
s1 x f1
=
s2 x f2
=
s3 x f3
Do đó
1 × f1
=
0.9 × f2
=
0.8 × f3
đồng thời với
f1 + f2 + f3 = 1.
Vậy thì
f1 = 36/121
f2 = 40/121
f3 = 45/121
Hai tập xác suất cân bằng Nash này nói cho mỗi tay chơi cách thức đo lường độ may rủi của cô ta hoặc ông ta trước khi gieo chúng. Hãy lưu ý – có lẽ rất đáng ngạc nhiên – kết quả mà người chạy trốn sử dụng những chiếc cầu rủi ro với xác suất cao hơn. Đó là cách duy nhất làm cho người săn đuổi trung lập với những gì liên quan đến chiếc cầu cô ta xí phần, và đến lượt mình nó lại tối đa hóa xác suất sống sót của người chạy trốn.
Chúng ta có thể giải trò chơi này một cách minh bạch vì chúng ta thiết lập hàm tiện ích sao cho nó trở thành zero-sum, hoặc cạnh tranh nghiêm nhặt. Thế có nghĩa là mỗi thành quả đạt được trong tiện ích mong muốn bởi một người chơi đều thể hiện một lần thua cân xứng một cách chính xác bởi tay chơi kia. Tuy nhiên có thể điều kiện này thường không đứng vững được. Giờ đây hãy giả sử rằng các hàm tiện ích đều phức tạp hơn nhiều. Người săn đuổi thích nhất một kết quả mà trong đó cô ta bắn người chạy trốn và vì vậy mà khẳng định lòng tin đối với hiểu biết của anh ta đối với một chiếc cầu mà anh ta chết vì đá rơi hoặc rắn cắn; và cô ta thích kết quả thứ hai hơn là để anh ta thoát được. Người chạy trốn thích một cái chết nhanh chóng bằng một phát đạn hơn là chết vì bị đá rơi, hoặc nỗi kinh hoàng khi bị rắn cắn. Tất nhiên điều anh ta thích nhất vẫn là thoát được. Như trước, chúng ta không thể giải được trò chơi này một cách đơn giản dựa trên cơ sở biết được các hàm tiện ích thứ tự của các tay chơi, vì các cường độ của những sở thích tương ứng giờ đây sẽ liên quan đến các chiến lược của họ.
Trước công trình của von Neumann & Morgenstern [1947], các tình huống thuộc loại này rõ ràng đã cản trở những người phân tích. Đó là vì tiện ích không chứng tỏ một biến số tâm lý ẩn dấu chẳng hạn như niềm vui sướng. Như chúng ta đã thảo luận ở phần 2.1, tiện ích chỉ là một phương tiện đo lường các cơ cấu hành vi có liên quan đem lại những định đề kiên định nào đó về các mối liên hệ giữa những sở thích và các lựa chọn. Vì vậy nó không tạo ra ý nghĩa để hình dung sự so sánh bản số của các tay chơi của chúng ta – có nghĩa là cường độ – nhạy cảm – các sở thích với bản số của người khác, vì không có tiêu chuẩn so sánh cố định liên cá nhân độc lập mà chúng ta có thể sử dụng. Vậy thì chúng ta có thể xây dựng mô hình các trò chơi thế nào để cho thông tin bản số phù hợp? Sau hết, việc xây dựng mô hình các trò chơi đòi hỏi rằng tất cả các tiện ích của những tay chơi đều phải được xem xét đồng thời như chúng ta đã thấy.
Một khía cạnh quyết định trong công trình của von Neumann & Morgenstern [1947] là giải pháp cho vấn đề này. Trong trường hợp này chúng tôi sẽ cung cấp một phác thảo tóm tắt về kỹ thuật khéo léo của họ trong việc xây dựng các hàm tiện ích bản số của các số thứ tự. Điều đó nhấn mạnh rằng cái tiếp theo chỉ là một phác thảo, sao cho có thể làm cho tiện ích bản số trở thành phi-bí ẩn đối với bạn với tư cách là một sinh viên, là người quan tâm đến việc tìm hiểu các cơ sở triết học của lý thuyết trò chơi, và về hàng lọat vấn đề có thể áp dụng. Việc cung cấp một chỉ dẫn cho bạn có thể được tiếp tục bằng việc xây dựng các hàm bản số của riêng bạn, phần chỉ dẫn đó sẽ chiếm nhiều trang giấy. Rất may là những chỉ dẫn như vậy lại có sẵn trong nhiều cuốn sách giáo trình. Trong bất kỳ trường hợp nào, nếu bạn là một sinh viên triết học thì bạn có thể không mong muốn thử làm công việc đó cho đến khi bạn tham gia vào một khóa học về lý thuyết xác suất.
Giả sử chúng ta có một tác nhân mà hàm tiện ích số thứ tự của tác nhân đó được biết rõ. Thực sự thì giả sử đó là người tù vượt sông của chúng ta. Chúng ta ấn định cho ông ta hàm tiện ích thứ tự sau:
Trốn thoát 4
Chết vì bị bắn 3
Chết vì đá rơi 2
Chết vì rắn cắn 1
Giờ đây chúng ta biết rằng ý muốn trốn thoát của ông ta hơn bất cứ kiểu chết nào chắc chắn mạnh hơn ý thích của ông ấy về, chẳng hạn bị bắn so với bị rắn cắn. Điều này sẽ được phản ánh trong hành vi lựa chọn của ông ta theo những cách sau. Trong tình huống chẳng hạn như trò chơi qua sông, ông ta sẽ mong muốn chạy thoát khỏi những rủi ro lớn hơn để tăng xác suất tương đối của việc trốn thoát so với bị bắn, và ông ta tăng xác suất tương đối bị bắn hơn là bị rắn cắn. Một chút logic ấy là sự hiểu biết hệ trọng đàng sau giải pháp của von Neumann & Morgenstern [1947] cho vấn đề bản số hóa.
Bắt đầu bằng việc đề nghị tác nhân của chúng ta lựa chọn từ tập kết quả đã có một kết quả tốt nhất và một kết quả tồi nhất. “Tốt nhất” và “tồi nhất” được xác định trong khuôn khổ lựa chọn duy lý: một tác nhân duy lý luôn luôn lựa chọn sao cho có thể tối đa hóa xác xuất của kết quả tốt nhất – ta gọi đó là W – và để tối thiểu hóa xác suất của kết quả tồi nhất – được gọi là L. Giờ đây chúng ta hãy xem xét các phần thưởng trực tiếp giữa W và L. Trong một tập kết quả chứa các phần thưởng như vậy, chúng ta phát hiện được điều may rủi bao gồm chỉ có W và L. Trong ví dụ của chúng ta đây sẽ là điều may rủi khi bị bắn và bị đá rơi như là những kết quả khả thể của nó. Ta gọi đó là may rủi T. Chúng ta định nghĩa một hàm tiện ích q = u(T) khi q là loại phần thưởng đáng mong đợi ở T, tác nhân thì trung tính giữa đạt được T và đạt được may rủi trong đó W xảy ra với xác suất u(T) và L xảy ra với xác suất 1 – u(T).
Giờ đây chúng ta xây dựng một T* may rủi đa hợp đối với tập kết quả {W, L} sao cho tác nhân là trung tính giữa T và T*. Một T may rủi đa hợp là một xác suất trong đó giải thưởng may rủi là một yếu tố may rủi khác. Điều đó là có ý nghĩa bởi vì trên hết nó vẫn là W và L là những yếu tố dang bị đe dọa đối với tác nhân của chúng ta trong cả hai trường hợp; vì vậy sau đó chúng ta có thể chia T* thành một may rủi đơn đối với W và L. Chúng ta gọi đây là may rủi r. Nó nảy sinh từ tính nhất thời mà T tương đương với r. (Lưu ý rằng điều này giả định trước rằng một tác nhân của chúng ta không đạt được hàm tiện ích từ tính chất phức tạp trong các canh bạc của cô ta). Giờ đây tác nhân duy lý sẽ chọn hành động tối đa hóa xác suất thắng W. Việc xây dựng sơ đồ từ tập kết quả đến u(r) là một hàm tiện ích von Newmann-Morgenstern (VNMuf).
Vậy thì thực sự là ở đây chúng ta đã làm được cái gì? Chúng ta chỉ đơn giản đưa ra cho các tác nhân những lựa chọn đối với các may rủi thay cho các lựa chọn đối với những phần thưởng một cách trực tiếp, và đã quan sát anh ta muốn thêm bao nhiêu rủi ro để chạy trốn để tăng cường những cơ hội thoát khỏi được rắn cắn liên quan đến việc bị bắn hoặc bị đá rơi trúng người. Một hàm tiện ích đạt được một bản số chứ không phải là một rãy thứ tự, một phép đo tiện ích. Lựa chọn của chúng ta về các giá trị điểm cuối, W và L là mang tính võ đoán như trước vậy; nhưng một khi những giá trị này đã được cố định thì các giá trị điểm trung gian cũng được xác định. Vì vậy hàm tiện ích VNMuf thực sự đo các cường độ sở thích có liên quan của một tác nhân đơn. Tuy nhiên vì việc chúng ta ấn định các giá trị tiện ích cho W và L là võ đoán, nên chúng ta không thể sử dụng các VNMufs để so sánh các sở thích bản số của một tác nhân với các sở thích của các tác nhân khác. Hơn nữa vì chúng ta sử dụng một trắc lượng rủi ro như một công cụ đo của chúng ta nên việc xây dựng hàm tiện ích mới phụ thuộc vào việc giả định rằng thái độ đối với tự thân sự rủi ro của tác nhân vẫn không đổi bằng việc so sánh các rủi ro với nhau. Điều này có vẻ là hợp lý đối với một tác nhân đơn trong một tình huống trò chơi đơn lẻ. Tuy nhiên hai tác nhân trong một trò chơi hoặc một tác nhân trong những loại hoàn cảnh khác nhau có thể thể hiện những thái độ rất khác nhau đối với rủi ro. Có lẽ trong trò chơi qua sông thì người săn đuổi mà cuộc sống của cô ta không hề bị đe dọa sẽ thích đánh bạc với vinh quang của cô ta trong khi người chạy trốn thì lại phải rất thận trọng. Nói chung một tác nhân chống rủi ro thích một phần thưởng được đảm bảo đối với một giá trị đáng mong đợi tương đương của nó trong một xác suất may rủi. Một tác nhân ưa rủi ro lại có một sở thích ngược lại. Một tác nhân trung tính với rủi ro thì trung tính giữa các lựa chọn này. Tuy nhiên trong việc phân tích trò chơi qua sông chúng ta không thể so sánh các tiện ích bản số của người săn đuổi với người chạy trốn. Suy cho cùng thì cả hai tác nhân đều phát hiện ra các chiến lược cân bằng Nash của họ nếu họ có thể ước tính được các xác suất mà mỗi tác nhân sẽ ấn định cho các hành động của tác nhân kia. Điều đó có nghĩa là mỗi tác nhân phải biết cả hàm VNMufs, nhưng họ lại không cần cố để đánh giá một cách tương đối các kết quả đối với những kết quả mà họ mạo hiểm.
Giờ đây chúng ta có thể điền phần còn lại của ma trận cho trò chơi qua cầu mà chúng ta đã bắt đầu vạch ra ở phần 2. Nếu toàn bộ những thứ mà người chạy trốn quan tâm là sự sống và cái chết của anh ta chứ không phải là cách thức chết, và nếu toàn bộ những gì mà người săn đuổi quan tâm là ngăn chặn người chạy trốn thoát được thì giờ đây chúng ta có thể giải thích về tất cả các hàm tiện ích về phương diện bản số. Điều này cho phép chúng ta ấn định những tiện ích mong muốn được thể hiện bằng cách nhân lên các khoản được trả nguyên bản bằng các xác suất tương đương như những kết quả trong ma trận. Giả sử rằng người săn đuổi đợi ở cầu có rắn với xác suất x và ở cầu đá rơi với xác suất y. Vì các xác suất của cô ta qua ba chiếc cầu phải có tổng là 1 nên điều này ngầm ẩn rằng cô ta phải đợi ở chiếc cầu an toàn với xác suất 1- (x + y). Vậy là việc tiếp tục ấn định cho người chạy trốn một khoản nhận được là 0 nếu anh ta chết và là 1 nếu anh ta thoát, và người săn đuổi thì có khoản nhận được ngược lại với người chạy trốn thì ma trận hoàn chỉnh của chúng ta là như sau:
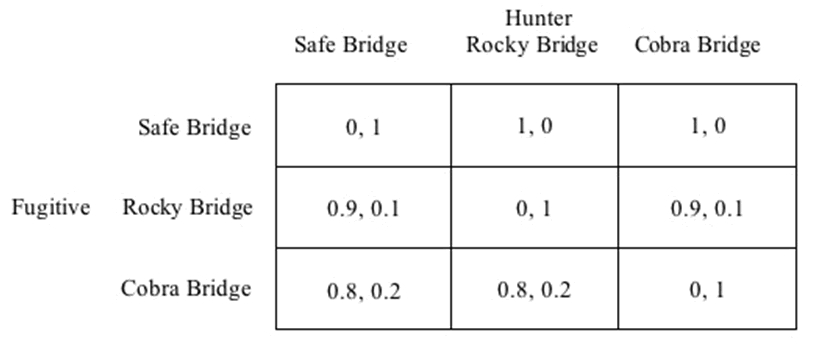
Hình 12
Chú thích hình 12:
– Cobra Bridge = cầu có rắn hổ mang
– Rocky Bridge = cầu có đá rơi
– Safe Bridge = cầu an toàn
– Fugitive = kẻ chạy trốn
– Hunter = người săn
Giờ đây chúng ta có thể đọc các sự kiện sau về trò chơi một cách trực tiếp từ ma trận. Không hàng nào cột nào thống trị nghiêm nhặt hoặc thống trị yếu đối với bất cứ hàng cột nào khác. Vì vậy các cân bằng Nash của trò chơi phải ở trong các chiến lược hỗn hợp.
3.1. Các niềm tin
Chúng ta cần lý giải như thế nào về các quá trình xây dựng mô hình bằng các thuật toán của các hỗn hợp cân bằng Nash trong các trò chơi như trò chơi qua sông? Một loại giải thích khả thể là loại lý giải tiến hóa. Nếu người săn đuổi và người chạy trốn thường xuyên chơi các trò chơi có cấu trúc tương tự với trò chơi qua sông thì những sức ép lựa chọn sẽ có những thói quen được cổ vũ trong họ là thứ đưa cả hai đến việc chơi các chiến lược cân bằng Nash và duy lý hóa hành động như vậy bằng việc thỏa mãn câu truyện hoặc cái khác. Nếu không bên nào ở trong tình huống như vậy và nếu các tổ tiên văn hóa và/hoặc sinh học của họ cũng chưa từng lâm vào tình huống như vậy, và nếu không bên nào quan tâm đến việc bộ lộ thông tin cho các đối phương trong những tình huống tương lai mong muốn thuộc loại này (vì họ không mong đợi họ lại xuất hiện) và nếu cả hai bên không phải là những lý thuyết gia trò chơi được đào tạo thì hành vi của họ sẽ được tiên đoán không phải bởi một lý thuyết gia trò chơi mà bởi những người bạn của họ, những người thân thuộc với những đặc tính cá nhân của họ. Các nhà hành vi luận sung sướng nhận ra rằng lý thuyết trò chơi không hữu dụng cho việc xây dựng mô hình mỗi hoàn cảnh kinh nghiệm chủ nghĩa khả thể là cái xuất hiện cùng.
Tuy nhiên nhà triết học nào muốn lý thuyết trò chơi được sử dụng như là một lý thuyết mô tả và/hoặc định chuẩn của tính duy lý chiến lược thì không thể cứ khăng khăng với câu trả lời đó. Ông ta phải tìm cho ra một cung cách tư vấn thỏa đáng cho những tay chơi ngay cả khi trò chơi của họ chỉ đơn độc trong cái vũ trụ của những vấn đề chiến lược. Không có lời khuyên nào như vậy có thể được đưa ra mà lại thỏa đáng không hề có tranh luận – sau rốt thì các nhà hành vi luận vẫn là các nhà hành vi luận vì họ không được thỏa mãn bởi bất cứ cách tiếp cận nào ở đây – nhưng có một cách xử lý vấn đề mà nhiều lý thuyết gia trò chơi đã phát hiện lại rất đáng để theo đuổi. Điều đó liên quan đến việc tính toán về những cân bằng trong niềm tin.
Thực ra thì nhà hành vi luận cũng cần khái niệm cân bằng trong các niềm tin, nhưng lại vì những mục đích khác. Như chúng ta đã thấy, khái niệm cân bằng Nash đã không được phân tích đủ sâu với tư cách một công cụ phân tích để nói cho chúng ta tất cả những gì mà chúng ta nghĩ là có thể quan trọng trong một trò chơi. Vì vậy ngay cả các nhà hành vi luận không phải chịu sức ép bởi dự án các bộ lọc cũng có thể tận dụng khái niệm cân bằng hoàn hảo của trò chơi phụ (SPE – subgame-perfect equilibrium) như đã được thảo luận trong phần 2.6, nếu họ nghĩ rằng họ đang phải đối phó với các tác nhân là những người được thông tin rất tốt (có nghĩa là vì họ ở trong một môi trường thể chế thân thuộc). Nhưng giờ đây chúng ta hãy xem xét trò chơi tay ba với thông tin hoàn hảo dưới đây được gọi là “Con ngựa Selten” (tên người sáng tạo ra trò chơi này, được giải thưởng Nobel, Reinhard Selten, và vì nó hình cây; lấy trích dẫn từ Kreps [1990, tr. 426]:
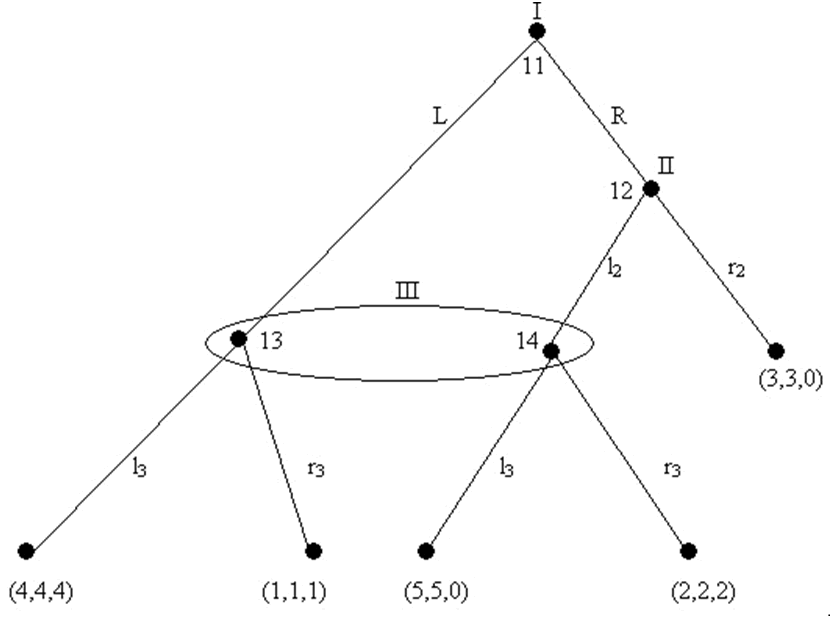
Hình 13
Một trong những cân bằng Nash của trò chơi này là Lr2l3. Đó là vì nếu tay chơi I chơi L, sau đó tay chơi II chơi r2không hề có động cơ để thay đổi chiến lược vì nút hành động duy nhất của bà ta, 12 đã trệch ra khỏi đường dẫn của trò chơi. Nhưng cân bằng Nash này dường như thuần túy kỹ thuật; nó đã tạo ra đôi chút ý nghĩa với tư cách là một giải pháp. Điều đó tự bộc lộ trong sự kiện là nếu trò chơi bắt đầu ở nút 14 có thể được xử lý như một trò chơi phụ, thì Lr2l3 sẽ không là một SPE. Bất cứ khi nào cô ta bắt đầu vận động thì tay chơi II cũng sẽ chơi l2. Nhưng nếu tay chơi II đang chơi l2 thì tay chơi I sẽ chuyển sang R. Trong trường hợp đó tay chơi III sẽ chuyển sang r3, bằng cách đưa tay chơi II trở về r2. Và đây là một “cảm biến” mới, cân bằng Nash: Rr2r3. I và II đều chơi một cách hiệu quả “tách ra” khỏi III.
Cân bằng Nash này chỉ “nhạy cảm” theo cùng một cách là một kết quả SPE trong một trò chơi thông tin hoàn hảo nhậy cảm hơn cân bằng Nash phi-SPE. Tuy nhiên chúng ta không thể chọn nó bằng cách áp dụng thuật toán Zermelo. Vì các nút 13 và 14 rơi vào bên trong một tập thông tin chung, nên Con ngựa Selten chỉ có một trò chơi phụ (ấy là toàn bộ cuộc chơi). Chúng ta cần có một khái niệm “anh em” nữa cho SPE là cái mà chúng ta có thể áp dụng trong những trường hợp thông tin không hoàn hảo, và chúng ta cần một thủ tục giải pháp mới để thay thế thuật toán Zermelo cho các trò chơi như vậy.
Hãy lưu ý rằng tay chơi III trong Con ngựa Selten đang băn khoăn tự hỏi xem anh ta chọn chiến lược của mình như thế nào. “Giả sử ta vận động” anh ta tự nhủ “thì nút hành động của ta tới được từ nút 11, hay từ nút 12?”. Nói cách khác, cái gì là những xác suất có điều kiện mà tay chơi III ở nút 13 hay 14 làm cho anh ta thực hiện một vận động? Vậy thì nếu các xác suất có điều kiện là cái mà tay chơi III băn khoăn, sau đó là cái mà tay chơi I và tay chơi II phải phỏng đoán khi họ lựa chọn các chiến lược của họ là các niềm tin của tay chơi III về các xác suất có điều kiện đó. Trong trường hợp này, tay chơi I phải phỏng đoán về các niềm tin cả tay chơi II về niềm tin của tay chơi III, và niềm tin của tay chơi III về niềm tin của tay chơi II và vv…,. Trong trường hợp này các niềm tin tương ứng không chỉ mang tính chiến lược như trước, vì chúng không hề là cái mà các tay chơi sẽ thực hiện một tập các khoản nhận được nhất định và các cấu trúc của trò chơi, mà về cái mà họ nghĩ là tạo nên ý nghĩa cho việc tìm hiểu nào đó hoặc ý nghĩa khác của xác suất có điều kiện.
Những gì là niềm tin nào về xác xuất có điều kiện có thể có lý mà các tay chơi mong đợi từ tay chơi khác? Lý thuyết gia định chuẩn có thể kiên trì về bất cứ cái gì mà các nhà toán học đã phát hiện về chủ đề này. Tuy nhiên rõ ràng là nếu điều này được áp dụng thì một lý thuyết trò chơi mà nó tích hợp sẽ không phải là sự thật của hầu hết mọi người. Nhà hành vi luận sẽ kiên trì đối với việc áp đặt các thói quen hành vi là cái mà một quá trình chọn lọc tự nhiên có thể xây dựng thành các sản phẩm. Có lẽ một số tạo vật khả thể có thể quan sát các thói quen tôn trọng qui tắc Bayes, là một khái quát hóa chân thật tối thiểu về xác suất có điều kiện mà một tác nhân có thể biết nếu nó biết bất cứ khái quát nào như vậy. Việc bổ sung thêm nhiều tri thức tinh vi về xác suất có điều kiện có nghĩa là sự tinh lọc cân bằng về niềm tin, hệt như một số lý thuyết gia trò chơi thích tinh lọc các cân bằng Nash. Bạn có thể tưởng tượng cái điều mà các nhà hành vi luận nghĩ về dự án đó!
Giờ đây chúng ta sẽ giới hạn sự chú ý của mình vào khái niệm cân bằng về niềm tin được tinh lọc ít nhất, một khái niệm có được khi chúng ta đòi hỏi các tay chơi suy lý theo nguyên tắc Bayes. Nguyên tắc Bayes nói với chúng ta về việc phải tính toán như thế nào về xác suất của một sự kiện F sinh ra thông tin E (được viết thành ‘pr(F/E):
pr(F/E) = [pr(E/F) ì pr(F)] / pr(E)
Từ nay trở đi chúng ta giả định rằng các tay chơi không giữ niềm tin mâu thuẫn với đẳng thức này.
Giờ đây chúng ta có thể xác định một cân bằng theo trật tự. Một cân bằng theo trật tự có hai phần: (1) một hồ sơ chiến lược Đ cho mỗi tay chơi, như trước, và (2) một hệ thống niềm tin à cho mỗi tay chơi. à ấn định cho mỗi tập thông tin h một phân phối xác suất trên các nút x trong h, với lời lý giải rằng đó là những niềm tin của tay chơi i(h) về vấn đề là tập thông tin của anh ta nằm ở đâu, mà tập thông tin h đã cho đó đã có được rồi. Vậy là một cân bằng tuần tự là một tập tham số ưu tiên của các chiến lược Đ và một hệ thống niềm tin à phù hợp với qui tắc Bayes đến mức bắt đầu từ mỗi tập thông tin h trong hình cây mà tay chơi i(h) đã chơi một cách tối ưu từ đó, cái điều đã cho mà anh ta tin là đã xảy ra ấy đã được sinh ra bởi à(h) và cái sẽ xảy ra trong các vận động tiếp theo được sinh ra bởi Đ.
Giờ đây chúng ta thể hiện khái niệm ấy bằng việc áp dụng cho Con ngựa Selten. Và chúng ta hãy xem lại cái cân bằng Nash không mấy thú vị Lr2l3. Giả định rằng tay chơi III ấn định pr(1) cho niềm tin của cô ta rằng nếu như cô ta thực hiện một chuyển động thì cô ta sẽ ở nút 13. Vậy là tay chơi II, được cấp cho một à(II) cố định phải tin tưởng rằng tay chơi III sẽ chơi l3, mà trong trường hợp đó chiến lược SE duy nhất của cô ta là l2. Vì vậy mặc dù Lr2l3 là một cân bằng Nash, nhưng nó lại không phải là một cân bằng SE. Tất nhiên đây chính là điều mà chúng ta mong muốn. Việc sử dụng nhu cầu kiên định trong ví dụ này là một cái gì đó đối chút tầm thường, vì vậy giờ đây chúng ta hãy xem xét một trường hợp thứ hai, cũng được dẫn từ trích dẫn từ Kreps [1990, tr. 429] :
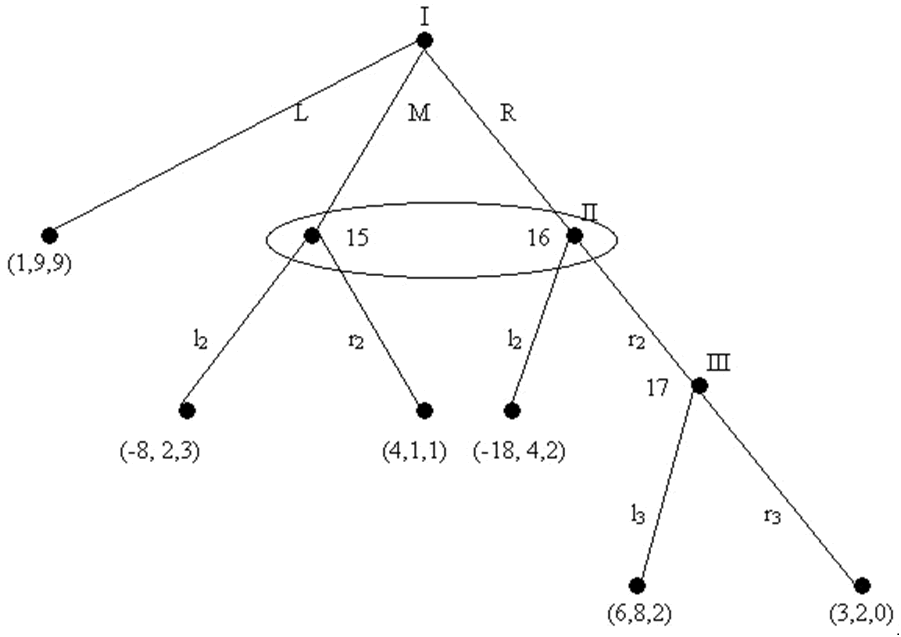
Hình 14
Giả sử rằng tay chơi I chơi L, tay chơi II chơi l2 và tay chơi III chơi l3. Cũng giả sử rằng à(II) ấn định pr(.3) cho nút 16. Trong trường hợp đó, l2 không phải là một chiến lược SE cho tay chơi II, vì l2 trở thành một khoản được trả đáng mong muốn là .3(4) + .7(2) = 2.6, trong khi r2 đem một khoản được trả đáng mong muốn là 3.1. Nên lưu ý rằng nếu chúng ta tiêu phí tập tham số ưu tiên chiến lược cho tay chơi III trong khi để cho mọi thứ còn lại cố định, thì l2 có thể trở thành một chiến lược SE cho tay chơi II. Nếu Đ(III) đạt được một cách chơi l3 với pr(.5) và r3 với pr(.5), thì nếu tay chơi II chơi r2 thì khoản được trả mong ước của anh ta giờ đây sẽ là 2.2, vì vậy Ll2l3 sẽ là một SE. Giờ đây hãy tưởng tượng môi trường à(III) quay trở lại như nó đã từng, nhưng hãy thay đổi à(II) sao cho tay chơi II nghĩ đến xác suất có điều kiện ở nút 16 lớn hơn .5; trong trường hợp này, l2 lại không phải là một chiến lược SE.
Ý tưởng về SE giờ đây đã hoàn toàn rõ ràng. Chúng ta có thể áp dụng nó vào trò chơi qua sông theo cái cách là nó tránh được tính chất nhất thiết cho người săn đuổi không phải gieo bất cứ đồng xu nào để chúng ta có thể làm cho trò chơi biến đổi đi đôi chút. Bây giờ hãy giả sử tay chơi II có thể thay đổi việc lựa chọn những chiếc cầu hai lần trong khi người chạy trốn đi qua, và sẽ bắt anh ta đúng trong trường hợp cô ta gặp anh ta khi anh ta rời chiếc cầu. Vậy thì chiến lược SE của người đi săn là chia thời gian của cô ta ở ba chiếc cầu phù hợp với tỷ lệ nhất định bằng phương trình trong đoạn thứ ba của phần 3 ở trên.
Cần phải lưu ý rằng vì nguyên tắc Bayes không thể được được áp dụng vào các sự kiện với xác suất bằng 0, nên việc áp dụng nó vào cân bằng SE đòi hỏi rằng các tay chơi phải ấn định các xác suất phi-zero cho toàn bộ các hành động có sẵn trong hình cây. Cần phải có đòi hỏi này vì giả sử là toàn bộ các tập tham số ưu tiên chiến lược được hòa trộn một cách nghiêm nhặt, có nghĩa là mỗi hành động đó ở mỗi tập thông tin được thực hiện với xác suất dương. Bạn sẽ thấy rằng đây thực sự cũng giống như việc giả định rằng toàn bộ các bàn tay đôi khi đều run. Một cân bằng SE là một dự án bàn tay run nếu toàn bộ các chiến lược chơi ở điểm cân bằng là những đáp trả tốt nhất đối với các chiến lược được hòa trộn một cách nghiêm nhặt. Bạn cũng không nên ngạc nhiên khi người ta nói rằng không chiến lược bị thống trị yếu nào có thể là dự án bàn tay run, vì khả năng của các bàn tay run đưa đến cho các tay chơi một lý do xác đáng nhất để tránh các chiến lược như vậy.
Còn nữa…
Tác giả: Don Ross là Giáo sư Triết học tại Đại học Alabama ở Birmingham, Giáo sư Kinh tế học tại Đại học Cape Town, Nam Phi. Công trình chủ yếu: Economic Theory and Cognitive Science: Microexplanation (MIT Press, 2005).
Nguyên văn: Game Theory, The Stanford Encyclopedia of Philosophy (Fall 2010 Edition), Edward N. Zalta (ed.), First published Sat Jan 25, 1997; substantive revision Wed May 5, 2010
Tài liệu dẫn
Baird, D., Gertner, R., and Picker, R. (1994). Game Theory and the Law. Cambridge, MA: Harvard University Press.
Binmore, K., Kirman, A., and Tani, P. (eds.) (1993). Frontiers of Game Theory. Cambridge, MA: MIT Press
Binmore, K. (1998). Game Theory and the Social Contract (v. 2): Just Playing. Cambridge, MA: MIT Press.
Camerer, C. (2003). Behavioral Game Theory: Experiments in Strategic Interaction. Princeton: Princeton University Press.
Danielson, P. (ed.) (1998). Modelling Rationality, Morality and Evolution. Oxford: Oxford University Press.
Fudenberg, D., and Levine, D. (1998). The Theory of Learning in Games. Cambridge, MA: MIT Press.
Fudenberg, D., and Tirole, J. (1991). Game Theory. Cambridge, MA: MIT Press.
Gintis, H. (2004). Towards the Unity of the Human Behavioral Sciences. In Philosophy, Politics and Economics 31:37-57.
Guala, F. (2005). The Methodology of Experimental Economics. Cambridge: Cambridge University Press.
Hofbauer, J., and Sigmund, K. (1998). Evolutionary Games and Population Dynamics. Cambridge: Cambridge University Press.
Krebs, J., and Davies, N.(1984). Behavioral Ecology: An Evolutionary Approach. Second edition. Sunderland: Sinauer.
Kreps, D. (1990). A Course in Microeconomic Theory. Princeton: Princeton University Press.
Maynard Smith, J. (1982). Evolution and the Theory of Games. Cambridge: Cambridge University Press.
McMillan, J. (1991). Games, Strategies and Managers. Oxford: Oxford University Press.
Nash, J. (1950a). Equilibrium Points in n-Person Games. In PNAS 36:48-49.
Nash, J. (1950b). The Bargaining Problem. In Econometrica 18:155-162.
Nash, J. (1951). Non-cooperative Games. In Annals of Mathematics Journal 54:286-295.
Ormerod, P. (1994). The Death of Economics. New York: Wiley.
Rawls, J. (1971). A Theory of Justice. Cambridge, MA: Harvard University Press.
Robbins, L. (1931). An Essay on the Nature and Significance of Economic Science. London: Macmillan.
. Evolutionary Game Theory and the Normative Theory of Institutional Design: Binmore and Behavioral Economics.In Politics, Philosophy and Economics, forthcoming.
Ross, D., and LaCasse, C. (1995). Towards a New Philosophy of Positive Economics. In Dialogue 34: 467-493.
Samuelson, L. (1997). Evolutionary Games and Equilibrium Selection. Cambridge, MA: MIT Press.
Samuelson, L. (2005). Economic Theory and Experimental Economics. In Journal of Economic Literature 43:65-107.
Samuelson, P. (1938). A Note on the Pure Theory of Consumers’ Behaviour. In Econimica 5:61-71.
Selten, R. (1975). Re-examination of the Perfectness Concept for Equilibrium Points in Extensive Games. In International Journal of Game Theory 4:22-55.
Sigmund, K. (1993). Games of Life. Oxford: Oxford University Press.
Smith, V. (1982). Microeconomic Systems as an Experimental Science. In American Economic Review 72:923-955.
Sober, E., and Wilson, D.S. (1998). Unto Others. Cambridge, MA: Harvard University Press.
Tomasello, M., M. Carpenter, J. Call, T. Behne and H. Moll (2004). Understanding and Sharing Intentions: The Origins of Cultural Cognition. In Behavioral and Brain Sciences, forthcoming.
Vallentyne, P. (ed.). (1991). Contractarianism and Rational Choice. Cambridge: Cambridge University Press.
von Neumann, J., and Morgenstern, O., (1947). The Theory of Games and Economic Behavior. Princeton: Princeton University Press, 2nd edition.
Weibull, J. (1995). Evolutionary Game Theory. Cambridge, MA: MIT Press.
Yaari, M. (1987). The Dual Theory of Choice Under Risk. In Econometrica 55:95-115.
Young, H.P. (1998). Individual Strategy and Social Structure. Princeton: Princeton University Press.
Người dịch: Hà Hữu Nga
Nguồn: http://vanhoanghean.com.vn/


